本文重点介绍ML 算法及其类型,并提供包含示例代码和实际示例的完整列表。它解释了有监督、无监督、强化和深度学习模型如何基于数据进行训练、预测结果以及在各个行业推动 AI。
机器学习(ML) 是人工智能 (AI) 的一个子集,专注于创建从数据中学习并进行预测或决策的算法,而无需为每个任务进行详细编程。与遵循严格的准则不同,ML 模型识别模式并随着时间的推移提高其有效性。
掌握这些术语及其相关算法对于在不同领域有效利用机器学习至关重要,这些领域涵盖医疗保健和金融到自动化和人工智能应用。
在本文中,我们将探讨不同类型的机器学习算法,它们如何运作以及它们在现实世界中的应用,以加深您对其重要性和实际应用的理解。
什么是机器学习算法?
机器学习算法由规则或数学模型组成,这些规则或模型使计算机能够识别数据中的模式,并在没有直接编程的情况下生成预测或决策。这些算法分析输入数据,识别连接,并随着时间的推移提高效率。
它们如何工作:
l 在数据集上训练以识别模式。
l 在新数据上测试以评估性能。
l 通过调整参数来优化,以提高准确性。
机器学习算法驱动着推荐系统、欺诈检测和自动驾驶汽车等应用。
机器学习算法的类型
机器学习算法可以分为五种类型:
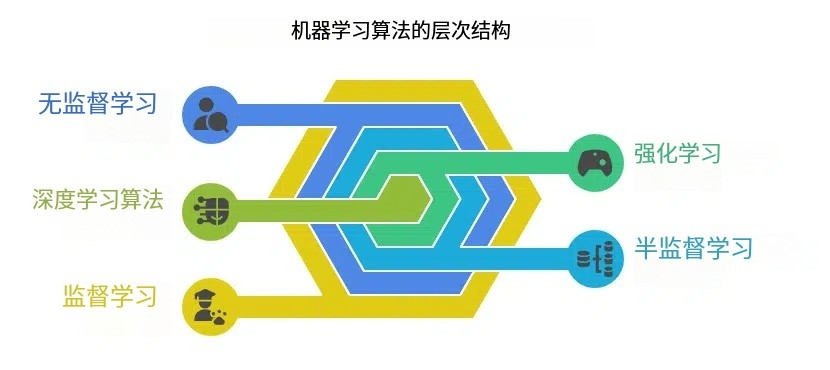
1.监督学习
2.无监督学习
3.强化学习
4.半监督学习
5.深度学习算法
1. 监督学习
在监督学习中,模型使用标记数据集进行训练,表明每个训练示例都包含一个输入-输出对。 该算法学习基于历史数据将输入与适当的输出相关联。
常见的监督学习算法:
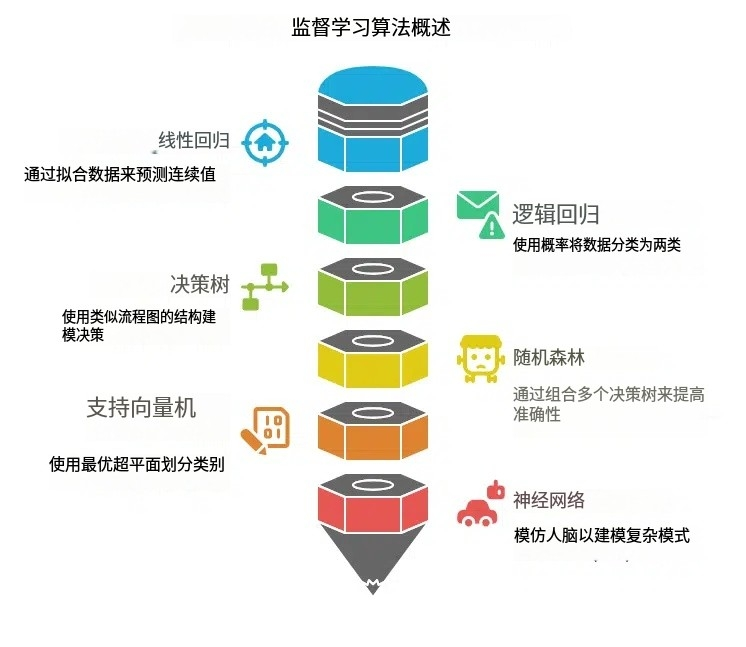
A. 线性回归
线性回归是一种基础算法,用于根据输入特征预测连续数值。它的工作原理是将一条直线(y=mx+b)拟合到数据,这条直线最能代表自变量和因变量之间的关系。
l 示例:考虑面积、卧室数量和地理位置等因素来估算房屋价值。
l 关键概念:它通过采用最小二乘法来减少观测值和估计值之间的差异。
B. 逻辑回归
虽然名称可能具有误导性,但逻辑回归实际上是用于分类而非回归。它使用sigmoid 函数将预测值转换为 0 到 1 的范围,这使其适用于二元分类问题。
l 示例:根据特定关键词的存在与否,判断电子邮件是否为垃圾邮件。
l 关键概念:使用概率将数据点分类到两个类别中,并应用阈值(例如,0.5)来做出决策。
C. 决策树
决策树是一种类似于流程图的模型,每个节点代表一个特征,每条分支代表一个决策,每个叶子代表一个结果。它能够处理分类和回归任务。
l 示例:银行根据收入、信用评分和就业历史决定是否批准贷款。
l 关键概念:根据特征条件分割数据,以最大化信息增益,使用诸如基尼不纯度或熵等指标。
D. 随机森林
随机森林是一种集成学习技术,它创建多个决策树并将它们的结果合并,以提高准确性并减少过度拟合。
示例:基于交易历史、人口统计信息和与客户服务的互动来预测客户是否会流失。
关键概念:使用自助聚合(bagging)生成不同的树,并平均它们的预测以提高稳定性。
E. 支持向量机 (SVM)
SVM是一种强大的分类算法,它寻找最佳超平面来分隔不同的类别。它对于类别之间有明显间隔的数据集特别有用。
示例:在MNIST数据集中对手写数字进行分类。
关键概念:使用核函数(线性、多项式、RBF)将数据映射到更高维度以实现更好的分离。
F. 神经网络
神经网络模仿人脑,由多层相互连接的神经元组成,这些神经元从数据中学习。它们被广泛应用于深度学习应用。
示例:自动驾驶汽车中的图像识别,用于检测行人、交通标志和其他车辆。
关键概念:由输入层、隐藏层和输出层组成,具有ReLU和Softmax等激活函数来模拟复杂模式。
监督学习的应用:
l 电子邮件垃圾邮件过滤
l 医疗诊断
l 客户流失预测
2. 无监督学习
无监督学习处理的是没有标记响应的数据。该算法在数据集中找到隐藏的模式和结构。
常见的无监督学习算法:
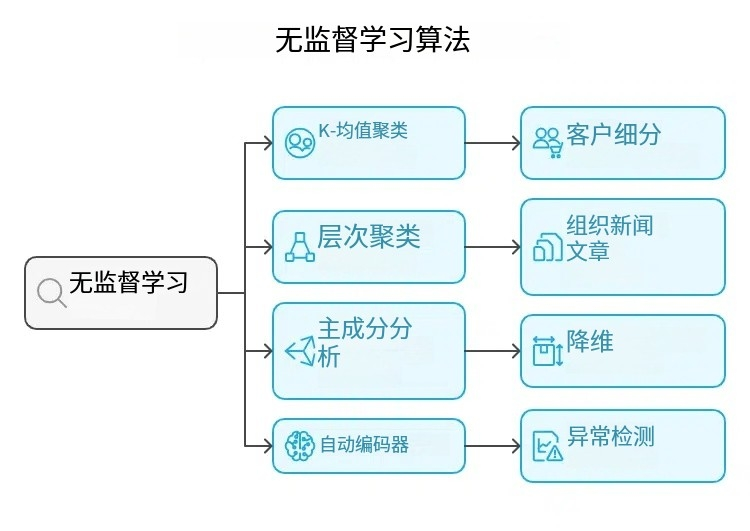
A. K均值聚类
K均值是一种流行的聚类算法,它将相似的数据点分组到 K 个簇中。 它将每个点分配到最近的簇中心,并迭代更新簇中心以最小化簇内的方差。
示例:电子商务中的客户细分,其中根据用户的购买行为将用户分组。
关键概念:使用欧几里得距离将数据点分配到簇,并更新簇中心直到收敛。
B. 层次聚类
层次聚类使用凝聚(自下而上)或分裂(自上而下)方法构建聚类的层次结构。它创建一个树状图来可视化聚类之间的关系。
示例:将新闻文章组织成基于主题的组,而无需预定义的类别。
关键概念:使用距离度量(例如,单链接、全链接)来合并或拆分聚类。
C. 主成分分析 (PCA)
PCA 是一种降维方法,它将高维数据转换为低维空间,同时保持关键信息。 它会找到主成分,即方差最大的方向。
示例:减少图像数据集中的特征数量,同时保留机器学习模型的关键模式。
关键概念: 使用特征向量和特征值将数据投影到更少的维度上,同时最大限度地减少信息损失。
D. 自编码器
自编码器是一种用于特征学习、压缩和异常检测的神经网络。它由编码器(压缩输入数据)和解码器(重构原始数据)组成。
示例:通过识别金融数据中的异常模式来检测欺诈交易。
关键概念:使用瓶颈层来捕获重要特征,并使用均方误差(MSE) 损失来重构数据。
无监督学习的应用:
l 客户细分
l 欺诈检测中的异常检测
l 推荐系统(例如,Netflix、亚马逊)
3. 强化学习
强化学习(RL) 涉及一个智能体学习与环境交互,以最大化随时间推移的奖励总和。
强化学习中的关键概念:
智能体 – 采取行动的实体。
环境 – 智能体运行的世界。
行动 – 智能体可以做出的选择。
奖励 – 指导智能体的反馈信号。
常见的强化学习算法:
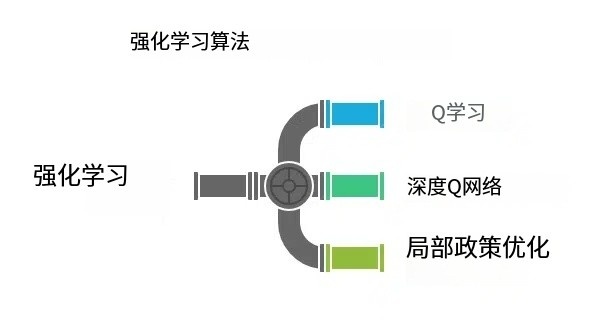
A. Q-学习
Q-学习是一种无模型的强化学习算法,通过Q表开发理想的行动选择策略。它遵循贝尔曼方程,根据从环境中获得的奖励更新Q值。
示例:训练一个AI代理玩像井字棋这样的简单游戏,通过学习哪些行动随着时间的推移能够带来胜利。
关键概念:使用ε-贪婪策略来平衡探索(尝试新行动)和利用(选择已知的最佳行动)。
B. 深度 Q 网络 (DQN)
DQN 是 Q-Learning 的扩展,它利用深度神经网络来近似 Q 值,使其适用于维护 Q 表不切实际的高维环境。
示例:教人工智能玩Atari 游戏,比如 Breakout,其中原始像素数据被用作输入。
关键概念:使用经验回放(存储过去的经验)和一个目标网络(稳定训练)来改善学习。
C. 近端策略优化 (PPO)
PPO是一种基于策略的强化学习算法,它使用信任区域方法来优化动作,确保更新的稳定性,并防止大的、破坏稳定的策略变化。
示例:训练机械臂有效地抓取物体,或使游戏AI能够在复杂环境中制定策略。
关键概念:使用裁剪的目标函数来防止过于激进的更新并提高训练稳定性。
强化学习的应用:
l 游戏博弈(例如,AlphaGo,OpenAI Gym)
l 机器人自动化
l 自动驾驶汽车
了解强化学习的基础知识,并使其在人工智能和机器人技术中做出决策。
4. 半监督学习
半监督学习介于监督学习和无监督学习之间,其中只有一小部分数据集被标记,其余未被标记。
应用:
l 语音识别
l 文本分类
l 医学图像分析
5. 深度学习算法
深度学习是机器学习的一个领域,它采用具有多个层(即,深度网络)的神经网络来发现原始数据的复杂属性。
流行的深度学习架构:
l 卷积神经网络(CNN) – 用于图像和视频分析。
l 循环神经网络(RNN) – 用于序列数据,如语音和文本。
l 生成对抗网络(GAN) – 用于图像生成。
应用:
l 面部识别(例如,Face ID)
l 自然语言处理(例如,ChatGPT、Google 翻译)
l 医学影像诊断
选择合适的机器学习算法
选择合适的机器学习算法取决于多种因素,包括数据的性质、问题类型和计算效率。
以下是选择正确算法的关键考虑因素:
1.数据类型:结构化和非结构化
2.问题类型:分类、回归、聚类或异常检测
3.准确性与可解释性:决策树易于解释,而深度学习模型更准确但更复杂。
4.计算能力:某些模型需要高计算资源(例如,深度学习)。
使用交叉验证和超参数调整等技术进行实验和模型评估对于选择性能最佳的算法至关重要。
Python 中的 ML 算法示例代码
Python 中的线性回归

Python 中的逻辑回归

Python 中的K均值聚类

Python 中的决策树分类器

支持Python 中的向量机 (SVM)

结论
机器学习算法是一组帮助AI 系统学习和执行任务的规则。它们用于发现数据中的模式或预测输入数据的结果。
这些算法是AI 驱动型解决方案的支柱。了解这些算法使您能够更有效地利用它们。













